Publications
MaterialFusion: Enhancing Inverse Rendering with Material Diffusion Priors
International Conference on 3D Vision (3DV) 2025
Arxiv
Website
- In this paper we tackle the intrinsic challenge of disentangling albedo and material properties from input images by incorporating a 2D prior on texture and material properties of 3D objects using a StableMaterial, a diffusion model which is trained on albedo, material, and relit image data derived from BlenderVault, a dataset of approximately ~12K artist-designed synthetic Blender objects containing high quality material assets.
KOROL: Learning Visualizable Object Feature with Koopman Operator Rollout for Manipulation
Conference on Robot Learning (CoRL) 2024
Arxiv
Website
- The paper proposes a learning based dexterous manipulation framework using Koopman operator that utilizes object features predicted by a spatial and frequency domain CNN-based feature extractor to auto-regressively advance system states. We evaluate our approach on simulated and real-world robot tasks, with results showing that it outperformed the model-based imitation learning NDP by 8% and the image-to-action Diffusion Policy by 16%.
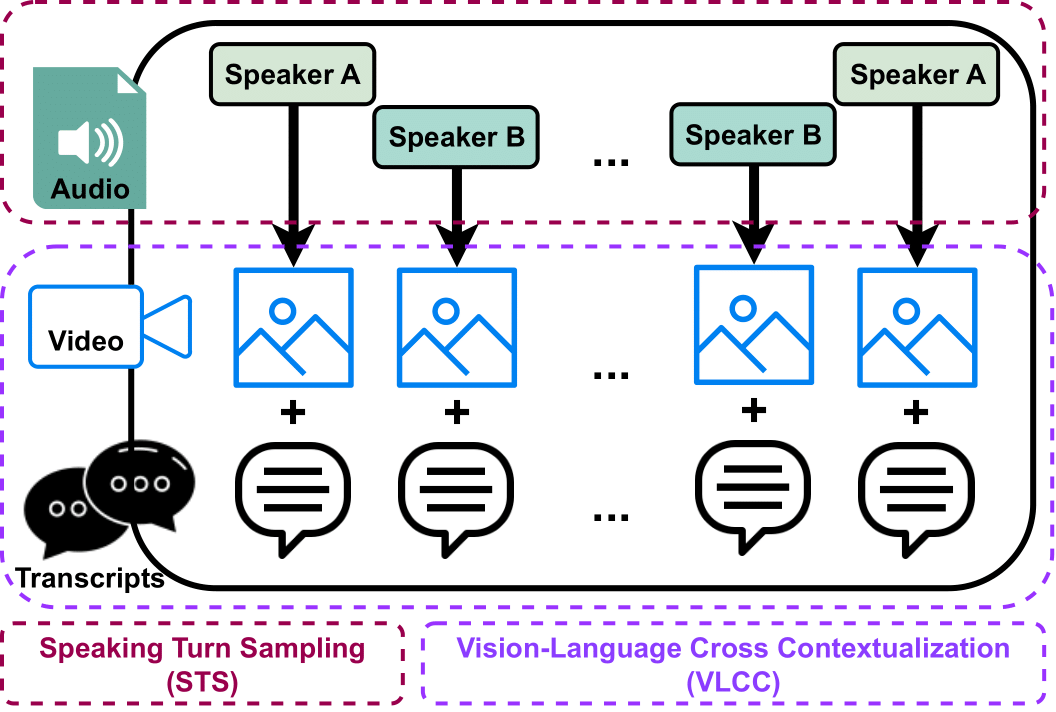
Listen Then See: Video Alignment with Speaker Attention
Conference on Computer Vision and Pattern Recognition (CVPR) 2024
Arxiv
Website
- The paper proposes a cross-modal alignment and subsequent representation fusion approach to help the Visual Question Answering task’s secondary modalities to work in tandem with the primary modality. We achieve state-of-the-art results (82.06% accuracy) on the Social IQ2.0 dataset for the task of Socially Intelligent Question Answering.
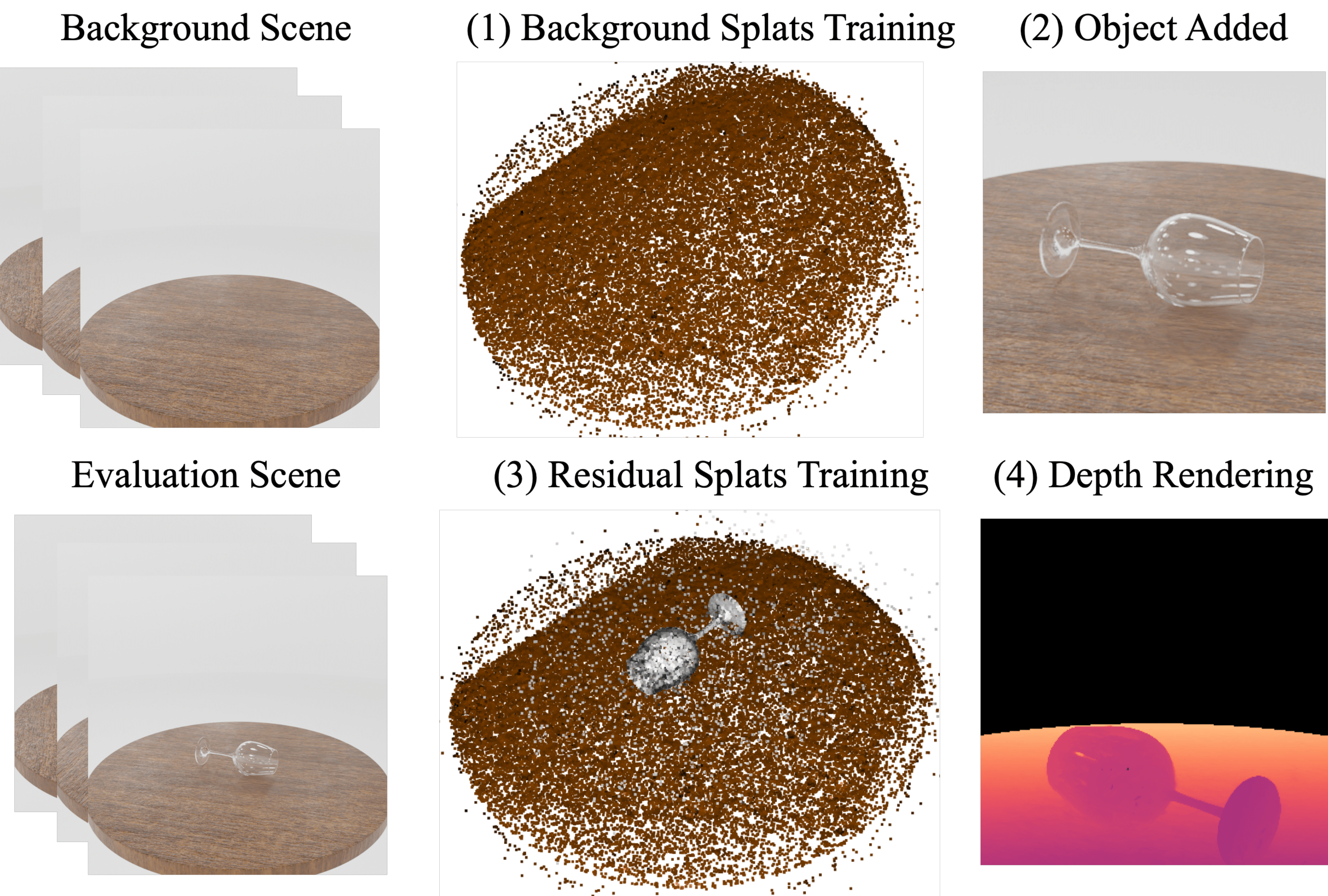
Clear-Splatting: Learning Residual Gaussian Splats for Transparent Object Manipulation
ICRA-2024 RoboNeRF workshop (Spotlight Presentation)
Arxiv
Website
- The paper proposes a method to leverage the scene-prior to first learn a Background Splat and subsequently learns a Residual Splat with the transparent object and the background combined. We also introduce Depth Pruning to address floaters. We achieve upto 67.09% lower RMSE and upto 87.80% lower MAE for depth estimation with transparent object compared to NeRF baselines.
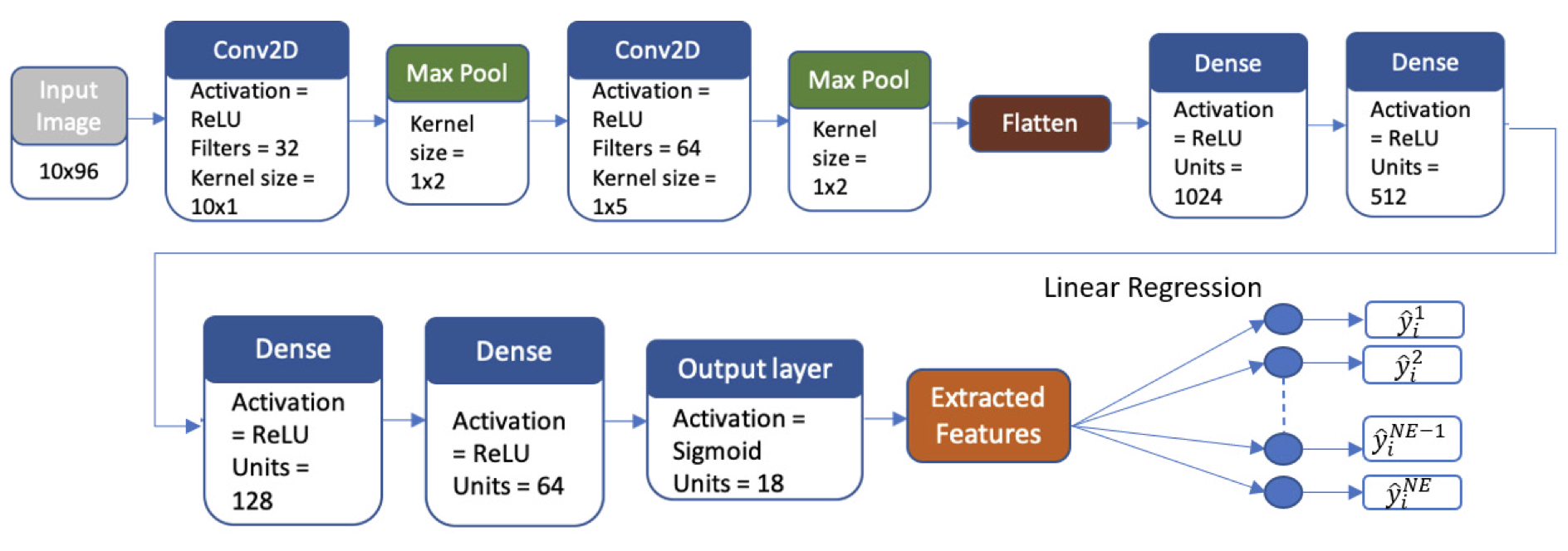
Development of a ML model for Damage Detection, Localization & Quant. to extend Structure Life [Link]
Mar 10, 2021 Elsevier B.V.
Arxiv
Website
- This paper proposes the use of a physical structure’s Transmissibility functions as input to a novel composite architecture consisting of Deep CNN followed by multivariate linear regressors to detect, localize, and quantify the damage extent in a system.
Patents
- Use frequency based image transformations for creating an efficient network leading to better video reconstruction in codecs.
- Train a plurality of models while capturing the quantization spectrum introduced by video codec
- Changes in video codec using these models to tackle every quantization band separately

- Train a model with domain-shifted feature-augmented training to overcome local nature of convolution
- Create a detachable model such that we use a much less complex model at the time of inference
- Train a plurality of models while capturing the quantization spectrum introduced by video codec
- Changes in video codec using these models to tackle every quantization band separately
- Train a model with domain-shifted feature-augmented training to overcome local nature of convolution
- Create a detachable model such that we use a much less complex model at the time of inference
- Capturing and fixing domain disparity in online video codec encoder operation
- Prevent model re-trainings earlier required to capture the infinite variation in video data
- Allow user choice between compression and performance by incorporating our solution in Rate-Distortion
- Identifying state-based data changes and variation in video compression pipeline
- Curation of AI-model training data by going beyond the current state, hence, training much more robust models
- Isolation of continual error-propagation through the video compression pipeline
- Removal/mitigation of temporally introduced distortions from training data generated through video codec for AI-models